現場の無駄をなくす、完全音声ワークフロー
スマートヘルメットが解決する現場の課題
- システムへの手動入力による「作業の中断」
- マニュアル確認のための「移動と検索のロス」
- トラブル発生時の「専門家との情報共有の遅れ」
- 事後の「報告書作成にかかる事務負担」
システムの圧倒的な優位性
PC手動操作より圧倒的に速い
従来の「PCやタブレットを手動で操作して資料を探す」行為を完全に音声対話へ置き換え。よりタイムリーかつ高効率に必要な情報を引き出します。
進捗のリアルタイム同期・手動報告ゼロ
多言語のリアルタイム音声対応により、作業の進捗は発話するだけで即座に更新。作業後の面倒な報告書の手入力作業から作業者を完全に解放します。
全記録・追跡・分析による「経験の永続的に蓄積」
すべての作業プロセスは全工程記録・追跡・分析が可能。現場で収集された大量のデータが企業のAIを絶えず学習・進化させ、熟練者の属人的な経験を企業のデジタル資産として永続的に蓄積・保存します。
ハードウェア仕様と機能
純粋な音声対話と、高度な環境モニタリングに特化したインテリジェント・デバイス。
従来型からの進化:能動的な安全管理と全記録
単なる物理的な頭部保護を目的とした従来の安全帽とは異なり、環境を能動的(プロアクティブ)に監視し、作業員を危険から未然に守り、すべての状況をデジタル記録する次世代のエッジソリューションです。
内蔵デバイス
DEVICES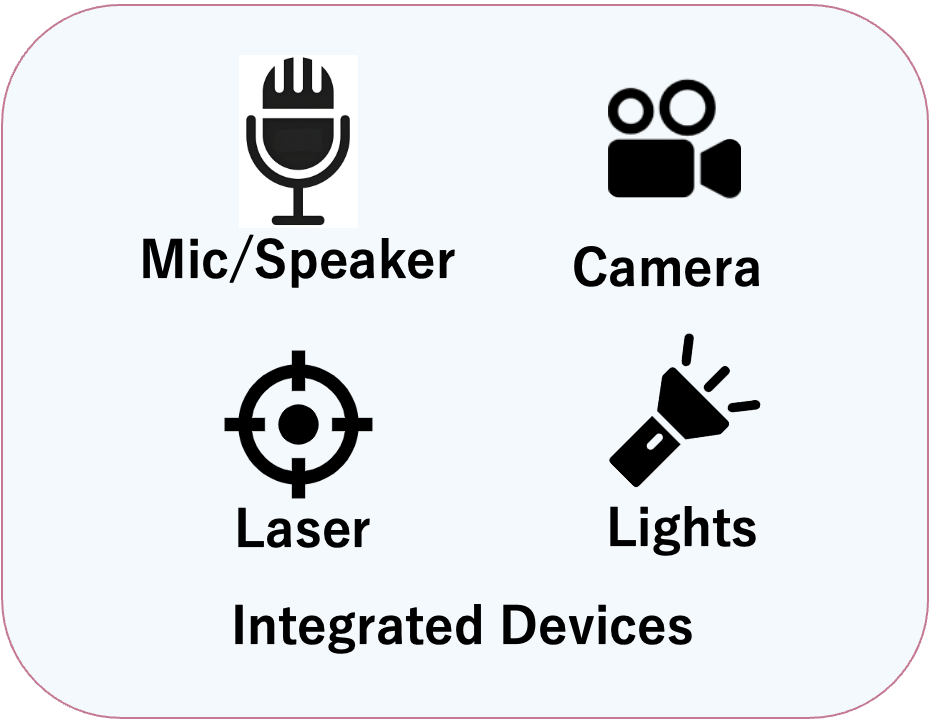
内蔵センサー
SENSORS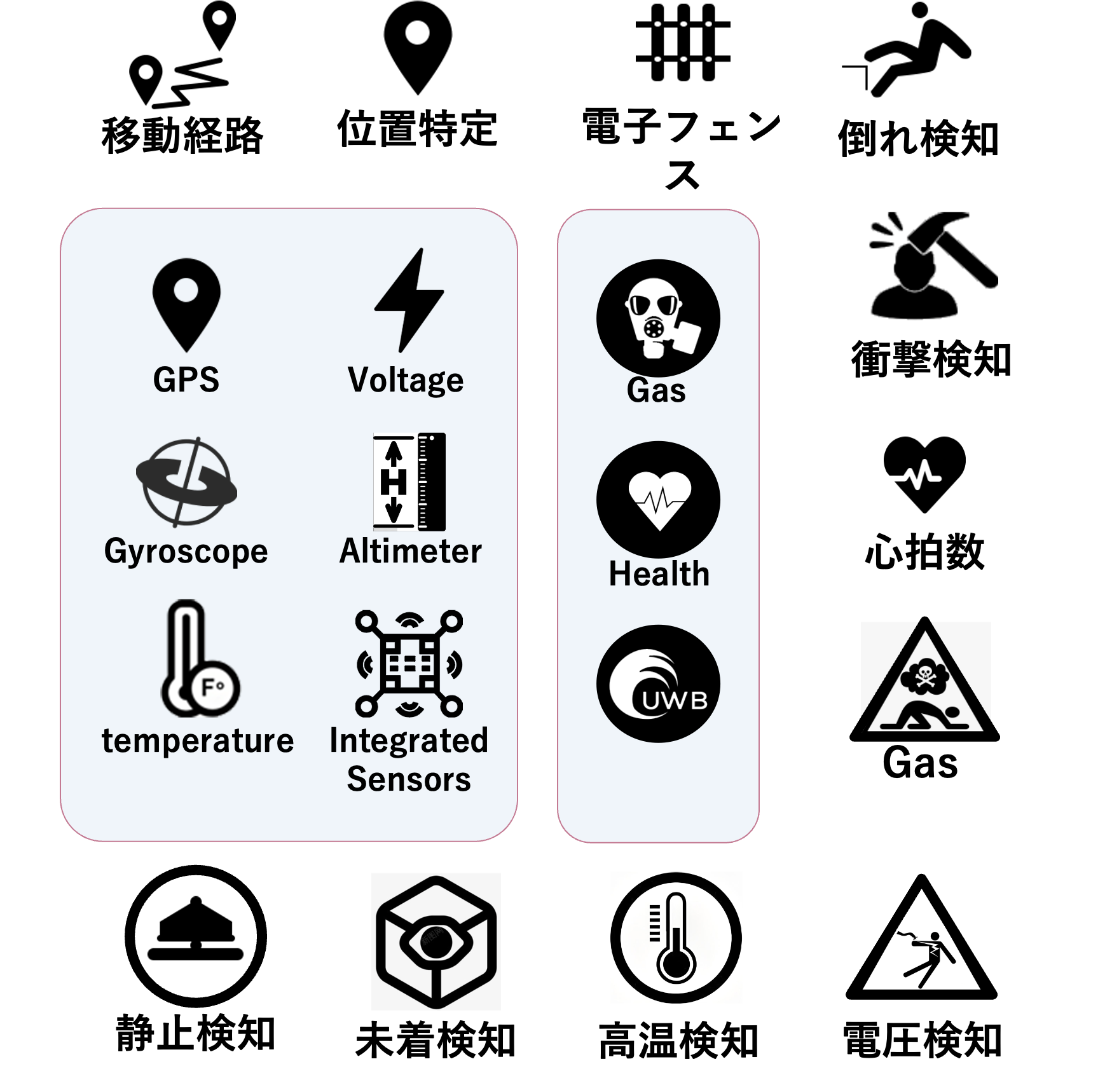
1. リアルタイム監視 Real-Time Monitoring
- 環境センサー: 温度、湿度、ガスレベルなどの環境要因を監視し、有毒ガスや異常な熱などの危険を検知します。
- アラートシステム: 安全でない状況が検知された場合、着用者と接続システムにリアルタイムでアラートを送信します。
2. 状況認識の強化 Situational Awareness
- 統合カメラ: 高解像度カメラが周囲の状況を捉え、潜在的なリスクの特定を支援します。
- LED照明 & レーザー: 低照度環境の視認性確保と、正確な位置決め・照準合わせをサポートします。
3. 接続性と通信 Connectivity
- 緊急通信: BluetoothおよびWi-Fiを搭載し、緊急時に管理者やチームとの即時通信を可能にします。
- GPSトラッキング: 着用者の位置を追跡し、緊急時や事故発生時の迅速な対応を実現します。
4. 能動的なデータ管理 Proactive Data
- エッジコンピューティング: ローカル処理により、危険な距離や不安定な足場の検出など、即座のフィードバックを提供。
- 集中監視: データをコントロールセンターへ送信し、管理者が状況を俯瞰してリスクに介入可能。
5. 安全プロトコルの統合 Protocol Integration
- カスタマイズ連携: 建設、鉱業、エネルギーなど、様々な業界固有の安全基準に合わせてシステムを構成。
- 自動異常アラート: 長時間の非アクティブや異常な動きを検知した場合、自動アラートで対応時間を短縮。
6. 環境耐久性とヘルスケア Durability & Health
- 防水・防塵 & 耐衝撃: 厳しい現場環境に耐えるIP67保護基準と、機能を損なわない堅牢な物理設計。
- 疲労検知モニタリング: センサーが心拍数や疲労の兆候を検知し、プロアクティブな健康管理を促進。
システム構成とデータ・エコシステム
音声とAIの連携で、ハンズフリーな現場ナビゲーションを実現。
現場データを継続学習し、熟練者のノウハウをデジタル資産化します。
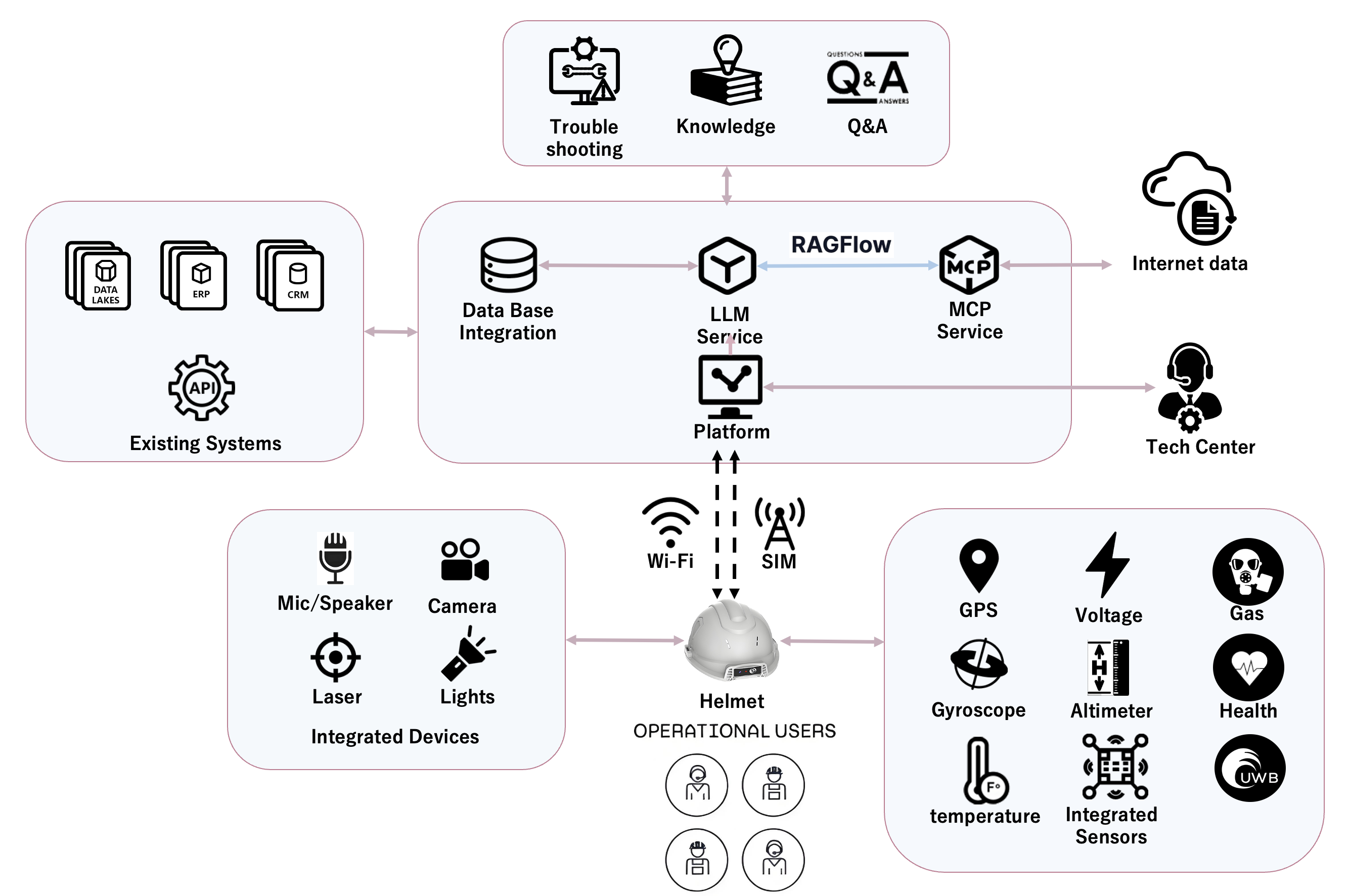
データ連携フロー
スマート安全帽が音声・映像・センサーデータをリアルタイムにクラウドへ送信。
LLMとRAGを活用し、作業者の音声を解析。膨大なマニュアルから最適解を即座に抽出。
既存のDBや基幹システムと連携し、タスクの更新や作業記録を全自動化。
AIで未解決の事象は、専門家へ映像・音声ごとシームレスにエスカレーション。
All Services Online
日常作業・作業指導・トラブルシューティングなど、現場のあらゆる業務をオンラインで統合し、全工程をトラッキングします。
ユーザーアクセスとセキュリティ
- シングルサインオンログイン
ワークフローおよびタスク管理
- インタラクティブチェックリスト
- 割り当ておよび保留中タスクの概要
- 完成した工程と進捗の概要
ハンズフリー操作および認識
- ナビゲーション操作の音声コントロール
- テキスト・QRコードなど認識
ガイダンス提供・ドキュメント
- ステップバイステップのワークフローガイド
- リファレンスドキュメントへのアクセス
- 技術文書の詳細閲覧
- AI搭載のセマンティック検索
コミュニケーションおよびトレーニング
- 報告用の写真・動画の記録
- 専門家支援のビデオ通話
- 新規ユーザー向けのトレーニングおよびデモモード
完全音声ワークフロー体験
作業者はマイクを通じてシステムと対話し、システムからのタスク受信、RAGによる障害対応、専門家へのビデオ通話エスカレーション、全工程のログ記録まで、一連のプロセスをシミュレーションします。
キーポイント:PC操作不要・リアルタイム進捗更新・事後報告書作成ゼロ。
作業者の音声コマンド(クリックして発話)
【導入事例】大手自動車工場における保全DX
導入企業:某大手自動車メーカー プレス工場 様
従来、作業者は点検やトラブルの度に「PCやタブレットを手動操作してマニュアルを探す」、または「作業後に事務所に戻り、手作業で報告書を作成する」といった非効率な環境にありました。
本ソリューションの導入により、現場の作業員は音声対話のみでAIやバックエンドシステムと連携。タイムリーかつ効率的な業務遂行が可能となり、現場での経験データはすべてAIへと永続的に蓄積・保存されています。
事例1 音声誘導と進捗リアルタイム同期
【導入前の課題】 紙のチェックリストやタブレット入力のため、工具から都度手を離す必要があった。管理者は作業が終わるまで進捗を把握できない。
【解決・導入後】 システム連携により、任務の下達から実績入力まで完全音声化。作業者は声で結果を報告するだけで、作業進捗がリアルタイムに同期・更新されます。
INTERACTIVE DEMO
AI音声: 「3号液圧プレスの油位を確認してください。正常ですか?」
AI音声: 「モータ温度計を確認してください。60度以下ですか?」
AI音声: 「全ての点検が完了しました。システムにデータを同期しますか?」
バックエンドシステム処理ログ
※リアルタイム同期導入効果とAIによる経験の永続的に蓄積
PC操作の排除と知識検索の即時化により、保守業務のあらゆるKPIが劇的に改善します。
従来のPC操作を音声対話で代替し、よりタイムリーで高効率に解決
作業進捗のリアルタイム同期により、事後の手作業による報告書作成が不要に
全工程の記録・分析により、企業のAIが大量データを継続学習し経験を保存
完全ハンズフリー化により、常に視線を設備に保ちながら作業を実行